


După 4 luni și mai mult de 600 de teste, a mai rămas o singură întrebare: dacă punem 5 tehnicieni de laborator profesioniști și sistemul AI în fața exact acelorași probe de grâu, vor ajunge la același rezultat?
Acesta a fost pragul de validare pe care l-am stabilit la începutul proiectului pilot. Fără criterii mai indulgente. Fără a face o medie a rezultatelor din condiții ideale. Cinci experți independenți, un sistem AI, o singură sesiune de testare — iar rezultatul urma să decidă dacă GrainODM intră în producție.
Acest studiu de caz descrie cum am ajuns aici.
De ce clasificarea calitativă a cerealelor este mai dificilă decât pare
Grâul nu este niciodată doar grâu. Când un lot ajunge la o bază de recepție, un tehnician specializat îl clasifică în funcție de zeci de parametri de calitate. În acest proiect pilot, am urmărit 18 categorii distincte de impurități, printre care:
- boabe afectate de fusarium (boală fungică)
- boabe de orz, ovăz, secară și hibrizi secară-grâu
- boabe sparte și boabe închise la culoare
- boabe atacate de dăunători, boabe mici / șiștave și boabe încolțite
- resturi vegetale, alte culturi, semințe străine, pleavă și totalul impurităților din boabe / corpurilor străine
O modificare în oricare dintre aceste categorii — chiar și de fracțiuni de procent — poate trece un lot de la Clasa 1 la Clasa 4, cu consecințe financiare directe.
Procesul este, de asemenea, inerent subiectiv. Doi tehnicieni experimentați care analizează același lot de boabe închise la culoare nu stabilesc întotdeauna același procentaj. Aceasta nu este o dovadă de lipsă de expertiză, ci însăși natura clasificării vizuale la nivel de bob, în condiții reale de lucru.
Acesta este exact motivul pentru care am ales să nu folosim ca etalon un singur tehnician. Cinci experți independenți ne-au oferit marja naturală de neconcordanță între specialiștii umani — și un prag relevant pentru măsurătorile noastre.
Dacă vrei să vezi cum tratează autoritățile de reglementare aceste limite la un nivel mai general, găsești mai multe detalii în ghidul nostru despre standardele pentru impurități în cereale.
Pentru o privire mai atentă asupra modului în care sunt detectate defecte punctuale, precum boabele încolțite, poți citi studiul nostru de caz despre detectarea boabelor încolțite în probele de grâu.
Faza 1: Proiectul pilot demarează — și apar cazurile dificile
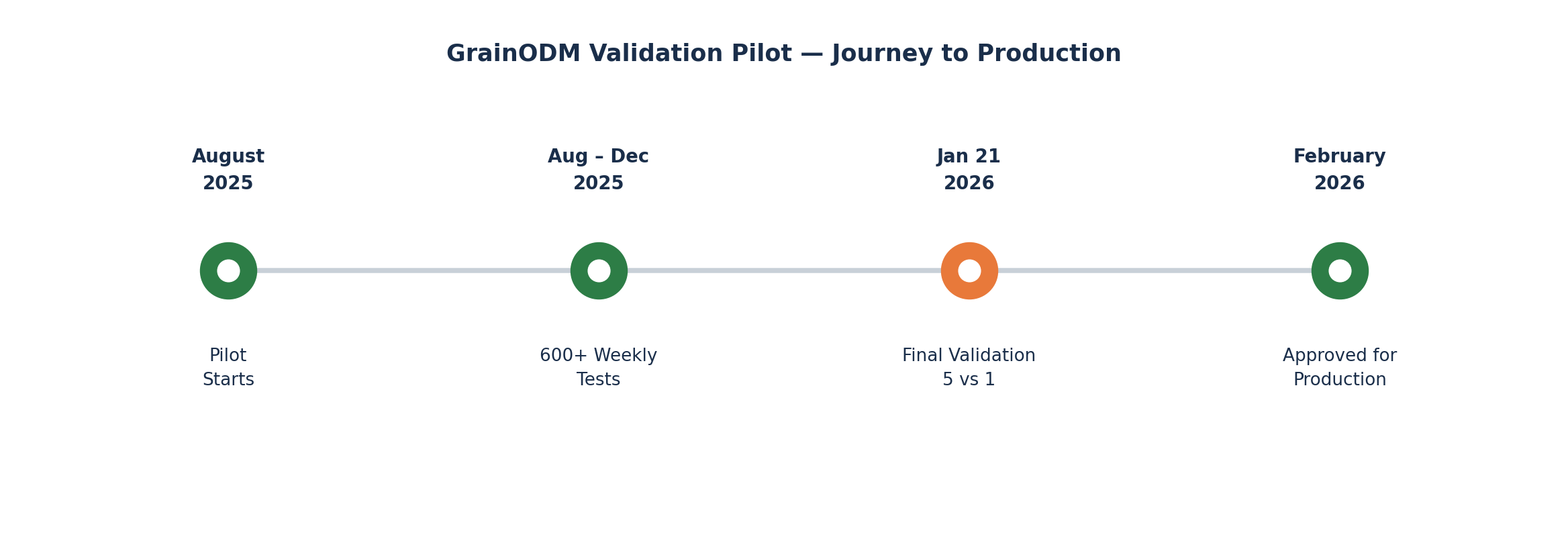
Proiectul pilot a fost lansat în august 2025, în parteneriat cu un mare holding agricol. GrainODM a rulat în paralel cu operațiunile de laborator existente ale clientului — analizând simultan aceleași loturi de grâu recepționate. Săptămânal, echipa noastră a revizuit rezultatele împreună cu clientul și a folosit constatările pentru a îmbunătăți modelul.
La finalul celor patru luni, am acumulat peste 600 de teste individuale.
Primele săptămâni au fost cele mai instructive. Trei categorii s-au dovedit a fi cele mai dificile:
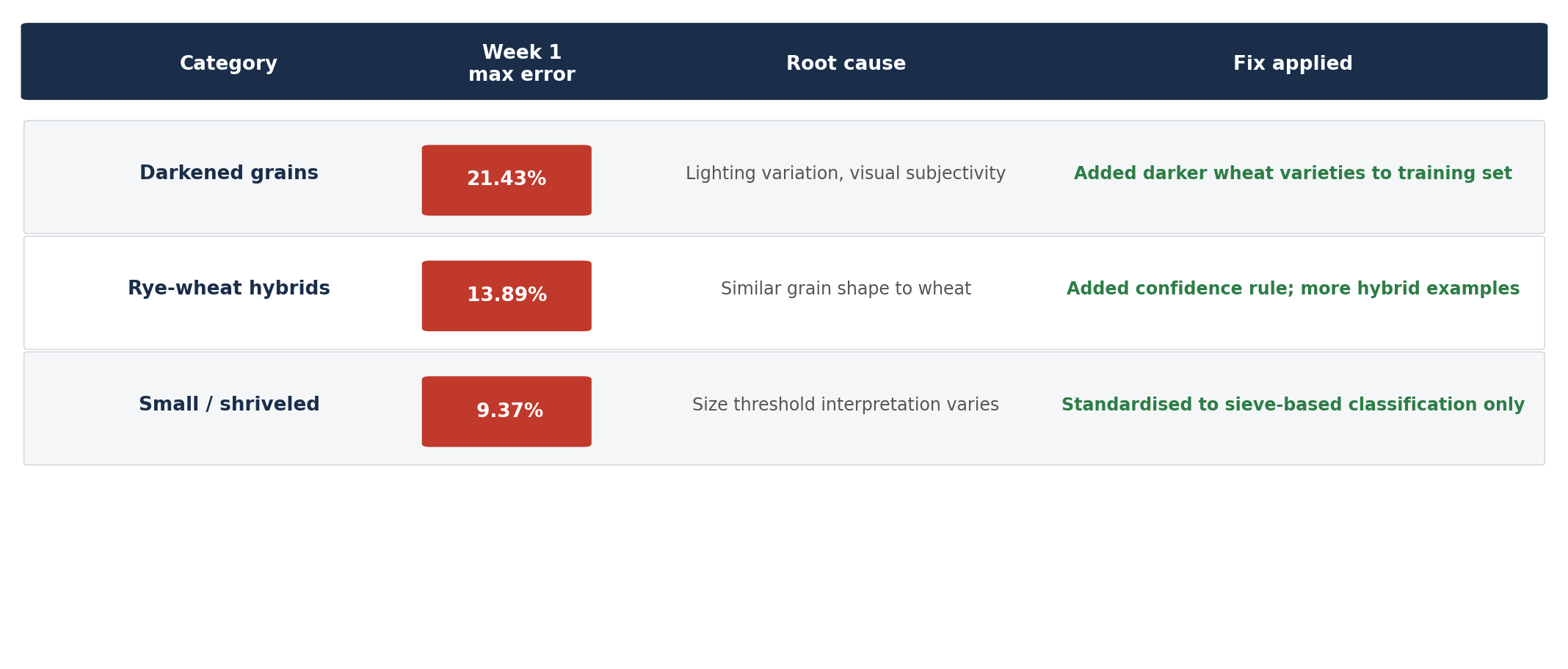
- Boabele închise la culoare au atins o discrepanță maximă de 21,43% în prima săptămână. Cauza principală: variațiile de iluminare la captarea imaginilor, combinate cu subiectivitatea inerentă a ceea ce înseamnă un bob „închis la culoare” — o evaluare pe care chiar și tehnicienii umani o făceau diferit în funcție de soiul de grâu.

- Hibrizii secară-grâu au prezentat o eroare maximă de 13,89%. Triticale — un hibrid de secară și grâu — are în comun suficiente caracteristici morfologice cu grâul, astfel încât modelul, neavând suficiente exemple, a întâmpinat dificultăți în a le deosebi în mod constant.

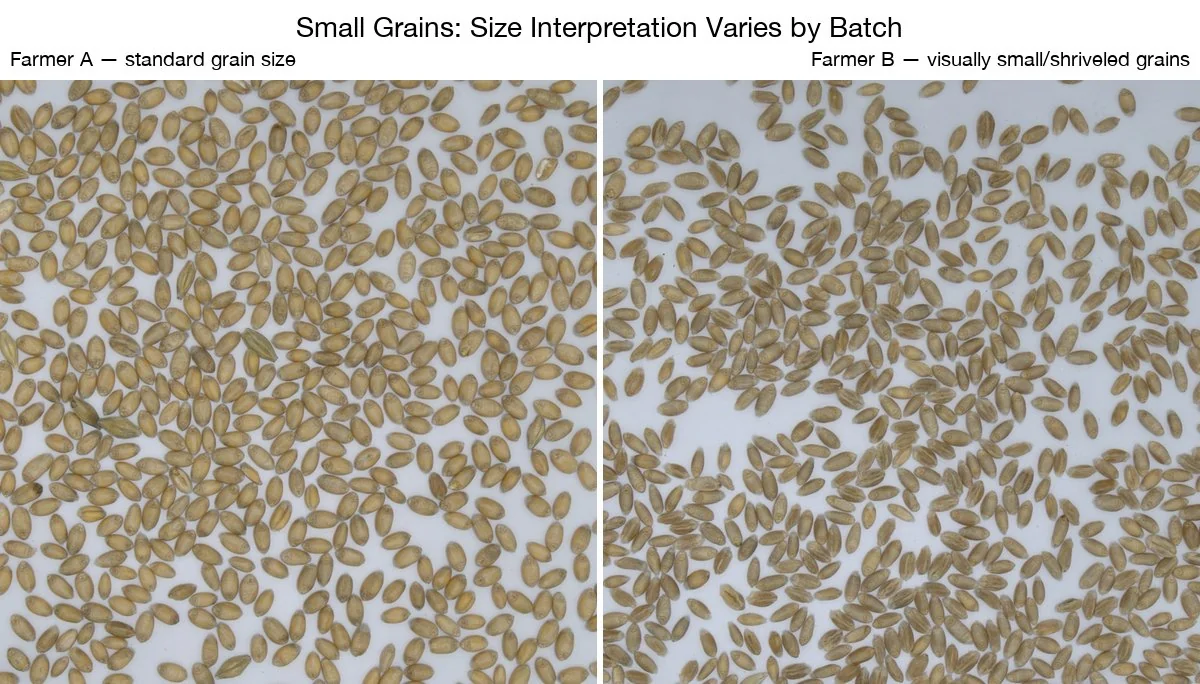
- Boabele mici / șiștave au atins 9,37%. Problema a fost o neconcordanță între modul în care modelul definea „mic” (vizual) și modul în care laboratorul definea acest parametru (pe baza calibrului sitei).
Acestea nu au fost erori aleatorii. Fiecare a avut o cauză clară, diagnosticabilă — ceea ce înseamnă că fiecare a avut și o soluție clară.
Bucla de feedback: de la date la îmbunătățire
Aceasta este partea din dezvoltarea AI care este cel mai ușor de subestimat. Modelul nu a fost un sistem fix, instalat și lăsat să funcționeze. Rezultatele fiecărei săptămâni au fost analizate, cauzele au fost identificate, iar datele de antrenament au fost actualizate. Mai multe probe. O etichetare mai bună. Reguli specifice pentru cazurile particulare.
Etapele de actualizare a modelului în timpul proiectului pilot:
| Când | Actualizare |
|---|---|
| Prima săptămână | Eliminarea boabelor ușor închise la culoare din setul de date; adăugarea mai multor exemple de soiuri de grâu sănătos |
| A doua săptămână | Implementarea unui prag de încredere pentru detectarea secarei — clasificările incerte sunt respinse, nu forțate |
| A cincea săptămână | Implementarea unui nou model: identificare îmbunătățită a hibrizilor secară-grâu și a boabelor mai deschise la culoare |
| A șasea săptămână | Actualizare Fusarium: adăugarea de exemple de fuzarioză roz și albă; rafinarea etichetării pentru cazurile cu simptome clare |
| A șaptea săptămână | Boabe mici: excluderea boabelor >2mm din categoria celor șiștave pentru alinierea la standardul de laborator bazat pe sită |
Tiparul este unul deliberat: identificăm unde deviază modelul de la evaluarea experților, înțelegem de ce, adăugăm mai multe date care acoperă acel caz, reantrenăm modelul și măsurăm din nou. Acesta este modul în care performanța unui sistem AI se îmbunătățește progresiv.
În aceeași perioadă, analizele săptămânale au scos la iveală un alt aspect. În mai multe probe, GrainODM a semnalat impurități pe care laboratorul le notase cu zero:
| Tip impuritate | Detecție GrainODM | Rezultat laborator |
|---|---|---|
| Boabe încolțite | 1,05% | 0,00% |
| Boabe încolțite | 0,95% | 0,00% |
| Boabe vătămate | 0,90% | 0,00% |
| Orz | 0,08% | 0,00% |
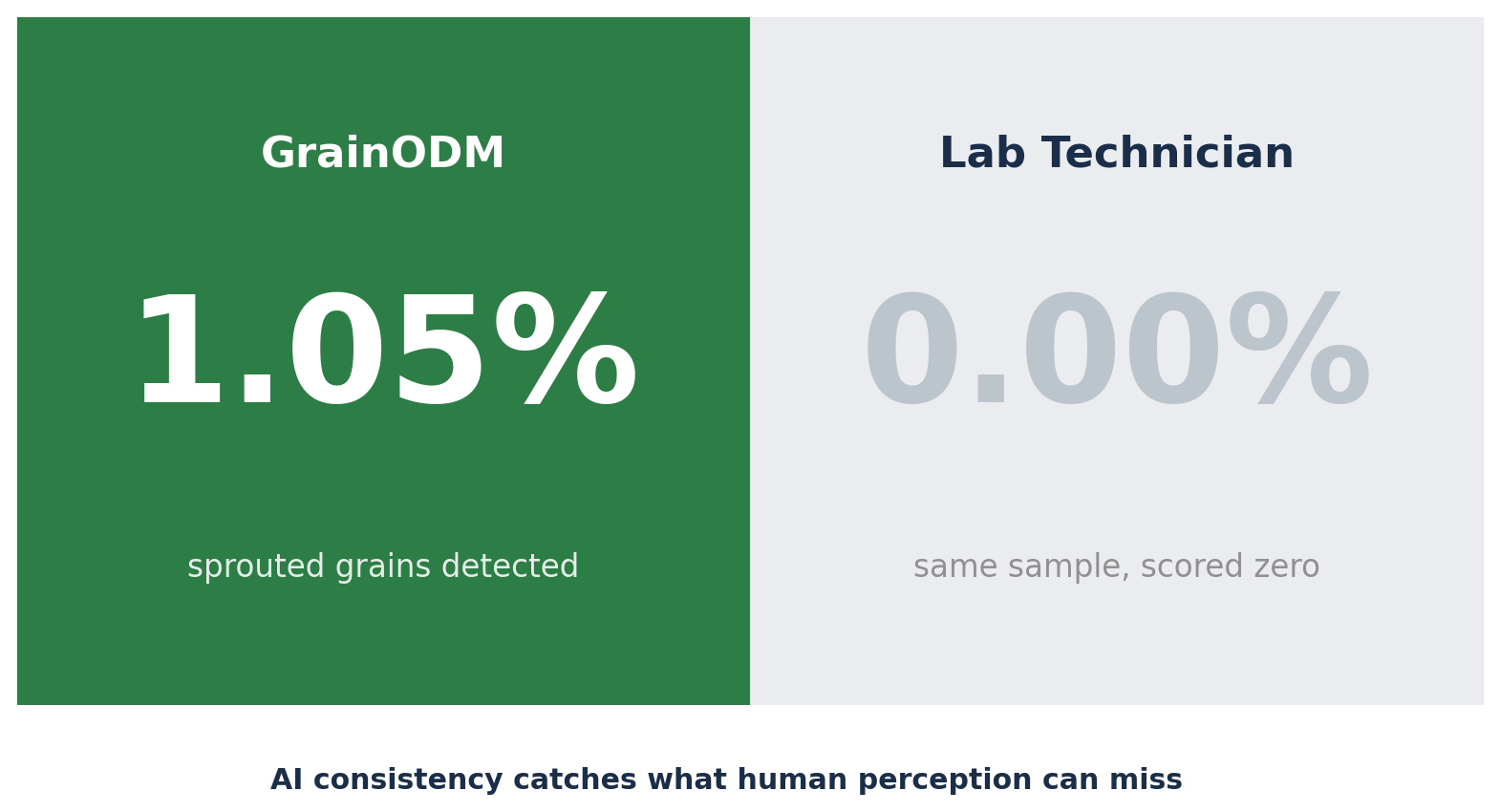
Sistemul AI nu greșea. Detecta la limita percepției umane — boabe individuale care pot fi trecute cu vederea în timpul unei ture lungi de lucru, într-un lot care pare curat la prima vedere. Consecvența în analiza fiecărui bob din fiecare probă este un domeniu în care mașinile sunt, în timp, pur și simplu superioare oamenilor.
Rezultatele buclei de feedback
Sfârșitul lui septembrie – îmbunătățirea era deja măsurabilă:
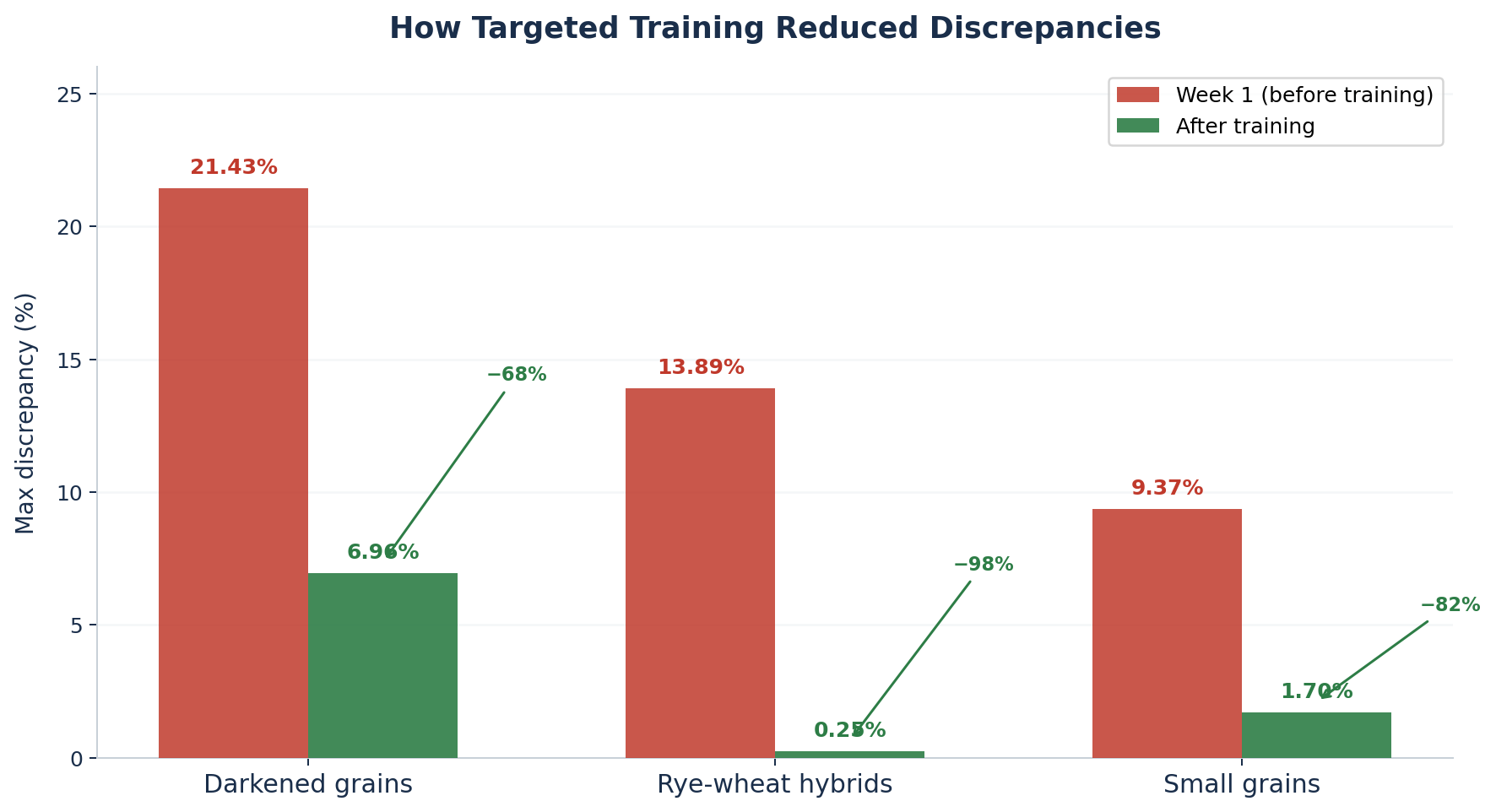
- Hibrizi secară-grâu: de la o discrepanță maximă de 13,89% la 0,25% — o reducere de 98%
- Boabe mici / șiștave: de la 9,37% la 1,70% — o reducere de 82%
- Boabe închise la culoare: de la 21,43% la 6,96% — o reducere de 68%
Fiecare îmbunătățire a provenit din același mecanism: date mai specifice, o etichetare mai bună și o definire mai clară a pragului de clasificare. Modelul nu a devenit mai inteligent în sens general — a devenit mai performant în cazurile specifice dificile, deoarece a fost antrenat cu mai multe exemple relevante.
Așa arată în practică dezvoltarea unui sistem AI.
Faza 2: Testul final
Pe 21 ianuarie 2026, după patru luni de testare în paralel, am desfășurat sesiunea formală de validare.
Cinci tehnicieni de laborator profesioniști au analizat independent 16 probe de grâu. GrainODM a analizat aceleași probe. Nimeni nu a văzut rezultatele celorlalți până la final. Fiecare probă a fost evaluată pentru 18 categorii de impurități, cu o clasificare calitativă completă.
Era momentul decisiv. Un rezultat pozitiv însemna trecerea sistemului în producție. Un eșec ne-ar fi întors la faza de proiectare.
Rezultatele
| Metrică | Rezultat |
|---|---|
| Concordanță AI cu cel puțin 1 tehnician | 96,2% |
| Concordanță AI cu 3 din 5 tehnicieni | 95% |
| Concordanța medie a AI cu toți tehnicienii | 93,5% |
| Concordanță AI simultană cu toți cei 5 tehnicieni | 85% |
Două categorii de impurități au atins 100% concordanță între AI și toți tehnicienii (pleavă și boabe încolțite), iar la altele – semințe străine, boabe vătămate – mai există loc de îmbunătățire.
Ce înseamnă cu adevărat aceste cifre
Iată contextul care conferă acestor rezultate o semnificație aparte.
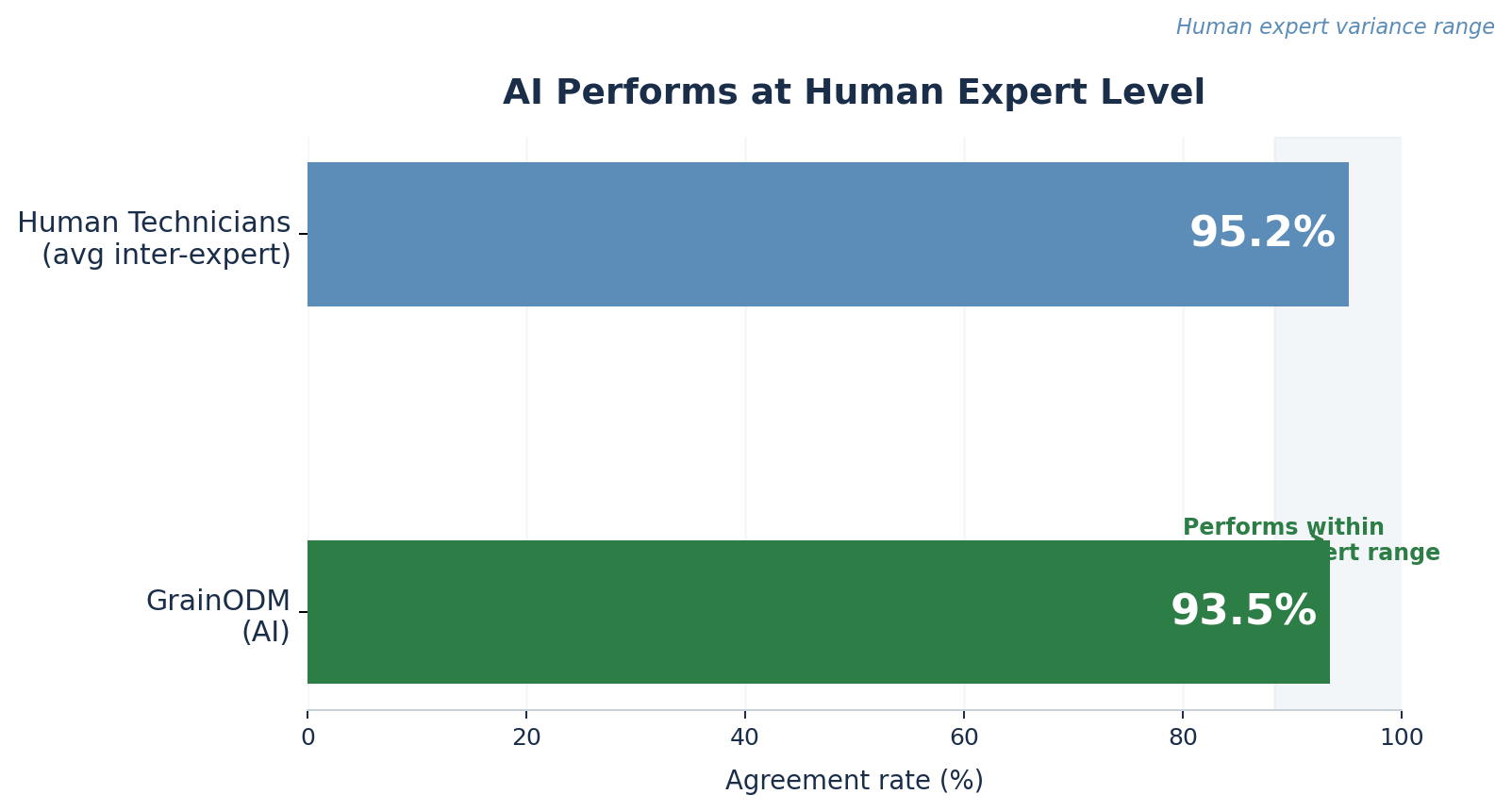
Atunci când cei cinci tehnicieni au clasificat aceleași probe în mod independent, concordanța medie între ei a fost de 95,2%. Sunt experți, dar sunt oameni — evaluarea subiectivă a unor distincții vizuale subtile înseamnă că nu ajung întotdeauna la exact același rezultat numeric.
GrainODM a obținut un scor de 93,5%.
Această cifră se încadrează în marja naturală de neconcordanță dintre experții umani. Nu doar că se apropie de această marjă, ci se plasează direct în interiorul ei. Sistemul AI performează la nivelul unui tehnician de laborator specializat. Adăugarea GrainODM într-un proces de evaluare este statistic echivalentă cu adăugarea unui al șaselea expert în echipă.
Pentru a pune această realitate și mai clar în context: atunci când cei cinci tehnicieni au evaluat aceleași 16 probe de grâu, în condiții identice și urmând același regulament de clasificare, nu au ajuns la o decizie unanimă privind clasa finală de calitate pentru 6 probe din 16. În 2 dintre cazuri, rezultatul a fost cu adevărat unul de tip „3 contra 2” – ceea ce înseamnă că același lot, evaluat de un alt grup de tehnicieni într-o altă zi, ar fi putut primi o clasă diferită.
Clasificarea la nivel de clasă de calitate rămâne, prin natura ei, un act de judecată profesională – chiar și atunci când toți lucrează după același set de reguli.
În acest punct, consistența devine esențială. GrainODM aplică aceeași logică fiecărei probe, de fiecare dată – fără diferențe între schimburi, fără oboseală acumulată, fără o „derivă” subiectivă a criteriilor în timp. Pentru aceiași parametri de intrare, sistemul produce aceleași rezultate; acest tip de comportament, la scară mare, nu poate fi garantat de niciun evaluator uman.
Decizia: aprobat pentru producție
Proiectul pilot a trecut pragul de validare. Rezultatele au arătat că AI poate lucra la nivel de expert în condiții reale de recepție.
Loturi reale de grâu. Clasificări cu impact financiar real. Rezultatele sistemului stau la baza deciziilor de încadrare calitativă a grâului — de la Clasa 1 la Clasa 4 — care determină prețul, condițiile de depozitare și utilizarea ulterioară. Acesta nu este un mediu de test. Miza este reală.
Ce înseamnă acest lucru pentru controlul calității cerealelor
Evaluarea calității cerealelor a necesitat întotdeauna personal calificat. Acest lucru nu se va schimba.
Ceea ce se schimbă este modul de distribuire a sarcinilor. Un sistem care performează la nivel de expert uman — consecvent pe mii de probe, fără să obosească, detectând la limita percepției umane — schimbă natura activităților pe care experții umani își concentrează timpul. Clasificarea de rutină devine automatizată. Cazurile excepționale, loturile ambigue, analiza tendințelor pe furnizori — acestea rămân în sarcina specialiștilor pregătiți să le analizeze.
Întrebarea nu a fost niciodată dacă AI poate înlocui tehnicienii de laborator. Întrebarea a fost: poate un sistem AI să performeze suficient de fiabil pentru a lucra alături de ei?
După 4 luni, peste 600 de teste și o validare formală în comparație cu cinci experți independenți, răspunsul este da.
Întrebări Frecvente
Pe 16 probe de grâu și 18 categorii de impurități, AI a arătat o concordanță medie de 93,5% cu cinci tehnicieni independenți. Concordanța între tehnicienii umani a fost de 95,2%, deci AI s-a situat în intervalul natural al judecăților experților.
Toate probele au venit din încărcături reale de grâu la o unitate comercială. AI și echipa de laborator au evaluat aceleași loturi în paralel pe aproximativ patru luni, acoperind sute de teste de recepție de rutină, nu un set de teste ales manual.
Categoriile cele mai dificile au fost boabele închise la culoare, hibrizii secară-grâu și boabele mici sau șiștave, plus fusarium. Reantrenarea țintită a redus semnificativ erorile la primele trei; îmbunătățirea clasificării fusariumului depinde în continuare de strângerea mai multor date etichetate de calitate.
Cifrele din acest studiu de caz se aplică grâului și standardelor de clasificare ale acestei unități. Procesul de validare – rularea AI în paralel, compararea cu mai mulți experți și iterarea asupra cazurilor cele mai dificile – poate fi repetat pentru alte culturi, unități și scheme de calitate.
The New Standard in Grain Purity Analysis
Data, not guesswork. Learn how GrainODM sets a new benchmark for digital grain inspection.