


Key Takeaways
L'IA a atteint 93,5 % de concordance avec cinq techniciens indépendants – dans la fourchette naturelle des jugements experts.
Les erreurs sur grains foncés, hybrides seigle-blé et petits grains ont fortement diminué après réentraînement ciblé sur les cas difficiles.
Le pilote a utilisé des échantillons réels de réception sur quatre mois, pas une démo lab – les résultats reflètent les conditions quotidiennes.
L'IA n'a pas remplacé le personnel ; elle a redistribué le temps : notation de routine automatisée, cas limites pour les experts.
Après 4 mois et plus de 600 tests, une ultime question demeurait : si nous placions 5 techniciens de laboratoire professionnels et l’IA face aux mêmes échantillons de blé, leurs analyses concorderaient-elles ?
Tel était le critère de validation que nous avions convenu au début du projet pilote. Aucune concession sur la référence. Aucune moyenne lissée sur des conditions idéales. Cinq experts indépendants, un système d’IA, une seule session — dont le résultat devait décider de la mise en production de GrainODM.
Cette étude de cas décrit comment nous y sommes parvenus.
Pourquoi l’évaluation de la qualité des céréales est plus complexe qu’il n’y paraît
Tous les blés ne se valent pas. Lorsqu’un lot arrive dans une installation, un technicien qualifié l’évalue selon des dizaines de paramètres : protéines et humidité par instruments, et une longue liste d’impuretés physiques encore jugées à l’œil.
Dans ce pilote, nous avons suivi 18 catégories d’impuretés, notamment :
- grains endommagés par la fusariose
- orge, avoine, seigle et hybrides seigle-blé
- grains cassés et foncés
- grains piqués, échaudés et germés
- débris, graines étrangères, gaillet, balles et impuretés grain/déchets (total)
Un écart dans n’importe quelle catégorie, même de quelques fractions de pourcent, peut faire passer un lot de la Classe 1 à la Classe 4, avec des conséquences financières directes. Pour en savoir plus sur la façon dont les réglementations traitent ces limites, voir notre guide normes d’impuretés des céréales.
Pour la détection de défauts comme les grains germés en labo traditionnel, voir l’étude de cas détection du germe sur blé.
L’évaluation est aussi intrinsèquement subjective. Deux techniciens expérimentés examinant le même lot de grains foncés n’aboutissent pas toujours au même pourcentage. Il ne s’agit pas d’un manque d’expertise, mais de la nature même de la classification visuelle à l’échelle du grain, en conditions réelles de travail.
C’est précisément pourquoi nous avons choisi de ne pas nous comparer à un seul technicien. Cinq experts indépendants nous ont fourni une marge de divergence naturelle entre experts humains, et donc une référence pertinente pour notre évaluation.
Phase 1 : Lancement du pilote et émergence des cas complexes
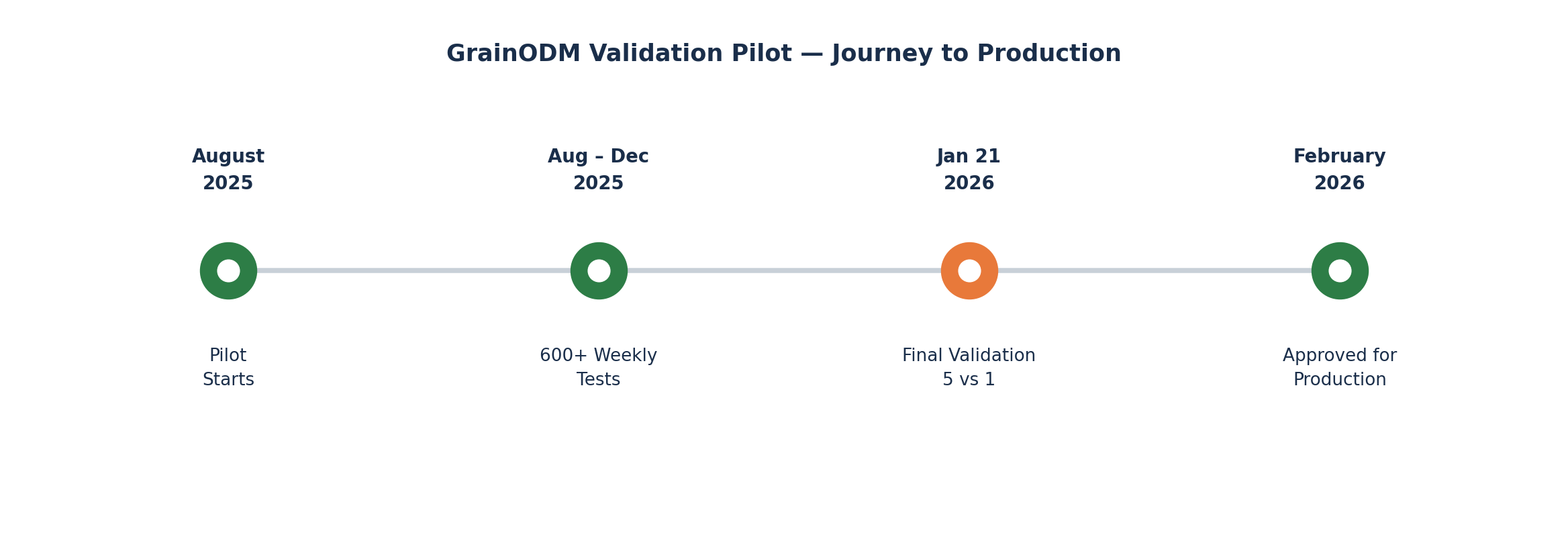
Le projet pilote a été lancé en août 2025 avec un grand groupe agricole. GrainODM fonctionnait en parallèle des opérations de laboratoire existantes du client, analysant simultanément les mêmes lots de céréales à leur arrivée. Chaque semaine, l’équipe examinait les résultats et intégrait les conclusions pour affiner le modèle.
Au bout de quatre mois, nous avions ainsi réalisé plus de 600 tests individuels.
Les premières semaines ont été les plus riches d’enseignements. Trois catégories se sont révélées particulièrement complexes :
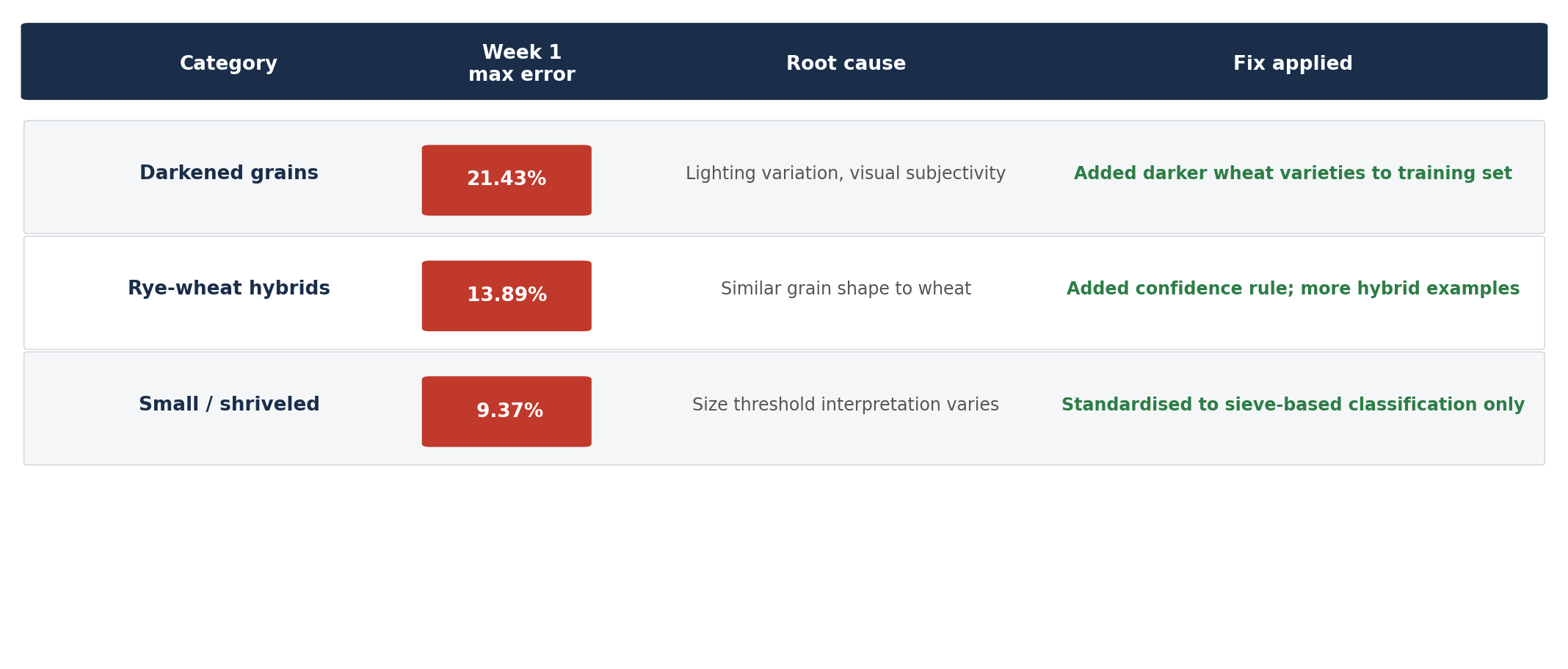
- Les grains foncés ont atteint une divergence maximale de 21,43% dès la première semaine. La cause principale : les variations d’éclairage lors de la capture d’image, combinées à la subjectivité inhérente à la définition d’un grain « foncé » — un jugement que même les techniciens évaluaient différemment selon la variété de blé.

- Les hybrides seigle-blé ont présenté un écart maximal de 13,89%. Le triticale, un croisement seigle-blé, partage suffisamment de caractéristiques morphologiques avec le blé pour que le modèle, sans assez d’exemples, peine à les distinguer de manière cohérente.

- Les grains petits / échaudés ont atteint un écart de 9,37%. Le problème venait d’un décalage entre la définition de « petit » par le modèle (visuelle) et celle du laboratoire (selon le calibrage au tamis).
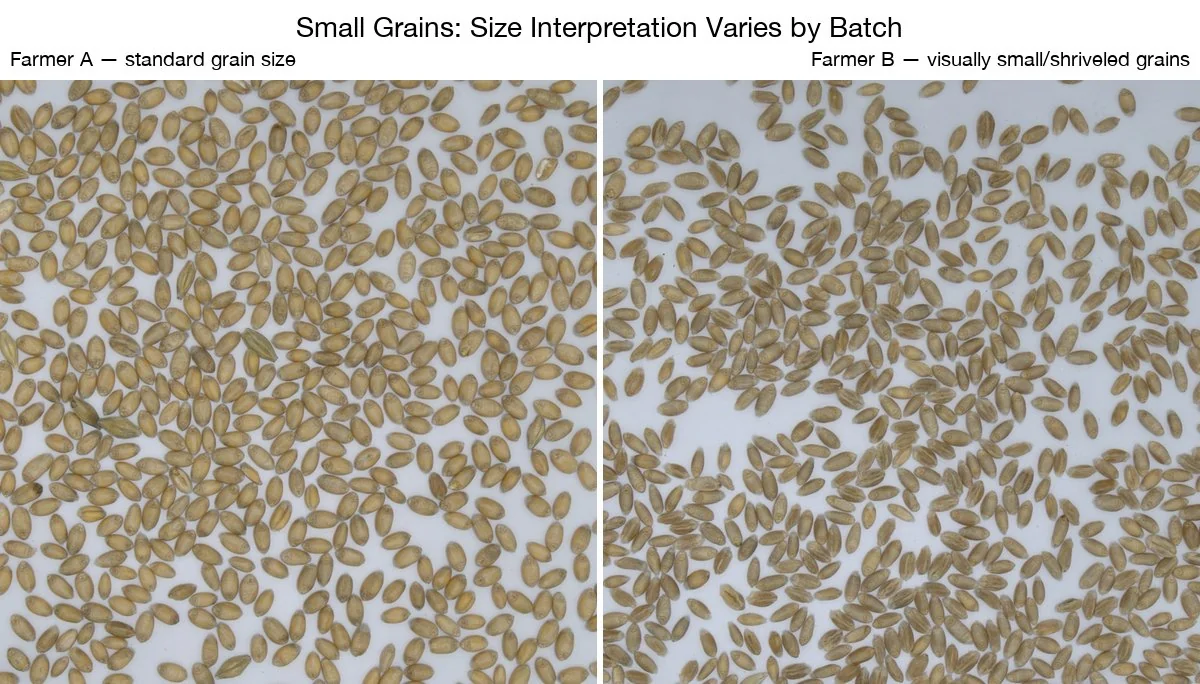
Il ne s’agissait pas d’échecs aléatoires. Chacun avait une cause clairement diagnostiquable et, par conséquent, une correction possible.
La boucle de rétroaction : des données à l’amélioration
C’est une partie du développement de l’IA qu’il est facile de sous-estimer. Le modèle n’était pas un système fixe, installé et laissé tourner en autonomie. Chaque semaine, les résultats étaient analysés, les causes profondes identifiées et les données d’apprentissage mises à jour. Plus d’échantillons. Un étiquetage plus précis. Des règles ciblées pour les cas limites.
Jalons de mise à jour du modèle pendant le projet pilote :
| Quand | Mise à jour |
|---|---|
| Première semaine | Suppression des grains légèrement foncés du jeu de données ; enrichissement des exemples de variétés de blé sain |
| Deuxième semaine | Implémentation d’une règle de confiance pour la détection du seigle : rejet des classifications incertaines |
| Cinquième semaine | Déploiement d’un nouveau modèle : meilleure gestion des hybrides seigle-blé et de la classification des grains clairs |
| Sixième semaine | Mise à jour Fusariose : ajout d’exemples de fusariose rose et blanche ; affinage de l’étiquetage pour les cas à symptômes clairs |
| Septième semaine | Petits grains : exclusion des grains >2mm de la catégorie “échaudés” pour correspondre à la norme du laboratoire basée sur le tamis |
La méthode est systématique : identifier où le modèle diverge du jugement des experts, comprendre pourquoi, ajouter des données couvrant ce cas de figure, relancer l’apprentissage et évaluer à nouveau les performances. C’est ainsi que les performances de l’IA progressent au fil du temps.
Pendant cette même période, un autre phénomène est apparu lors des bilans hebdomadaires. Dans plusieurs échantillons, GrainODM a signalé des impuretés que le laboratoire avait évaluées à zéro :
| Type d’impureté | Détection par GrainODM | Résultat laboratoire |
|---|---|---|
| Grains germés | 1,05% | 0,00% |
| Grains germés | 0,95% | 0,00% |
| Grains endommagés | 0,90% | 0,00% |
| Orge | 0,08% | 0,00% |
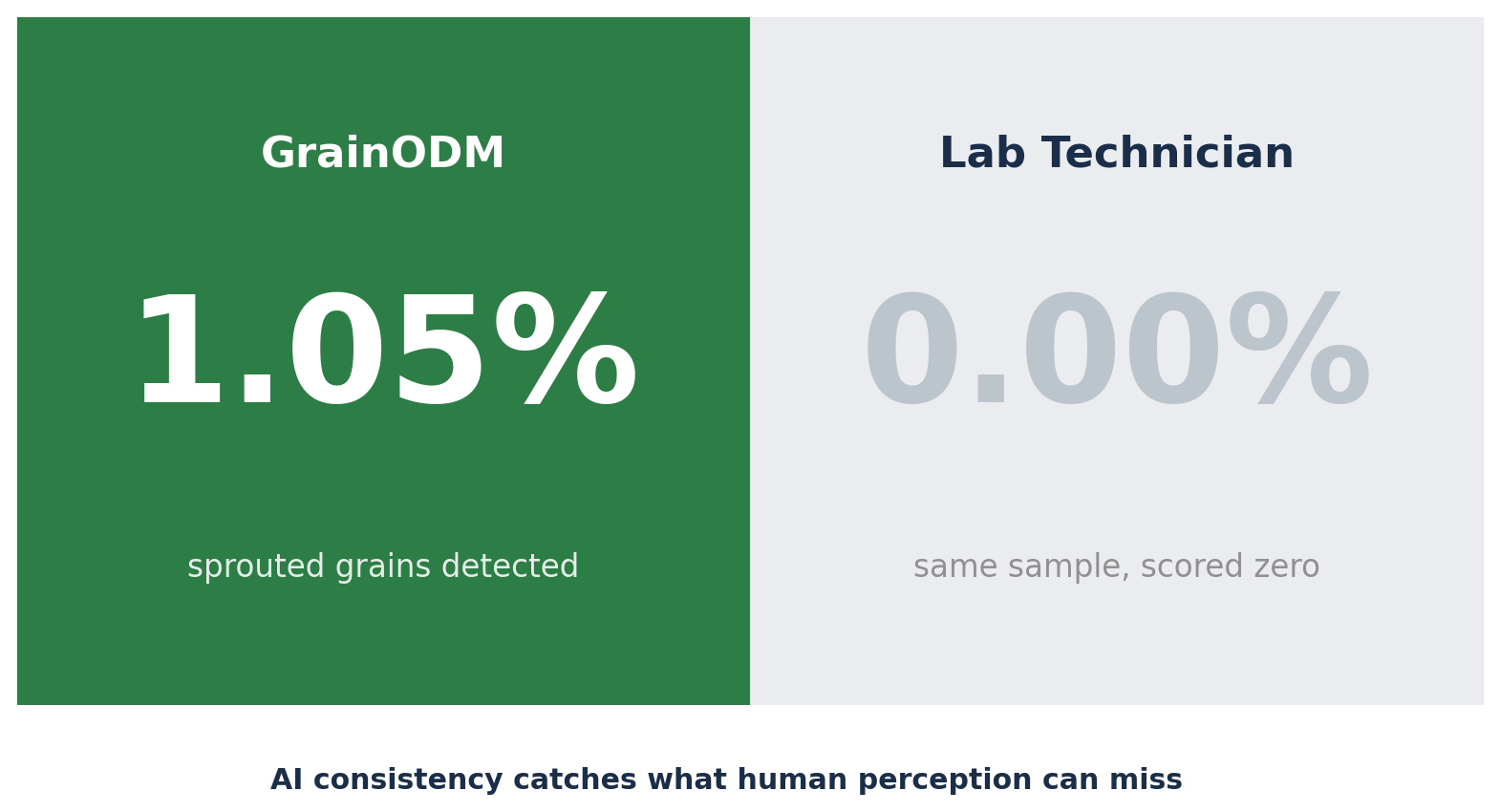
L’IA n’avait pas tort. Elle détectait à la limite de la perception humaine : des grains isolés qui peuvent échapper à l’œil lors d’une longue journée de travail, dans un lot d’apparence saine. La capacité à analyser chaque grain de chaque échantillon avec une constance absolue est un domaine où les machines surpassent les humains sur le long terme.
Les résultats de la boucle de rétroaction
Fin septembre, l’amélioration était quantifiable :
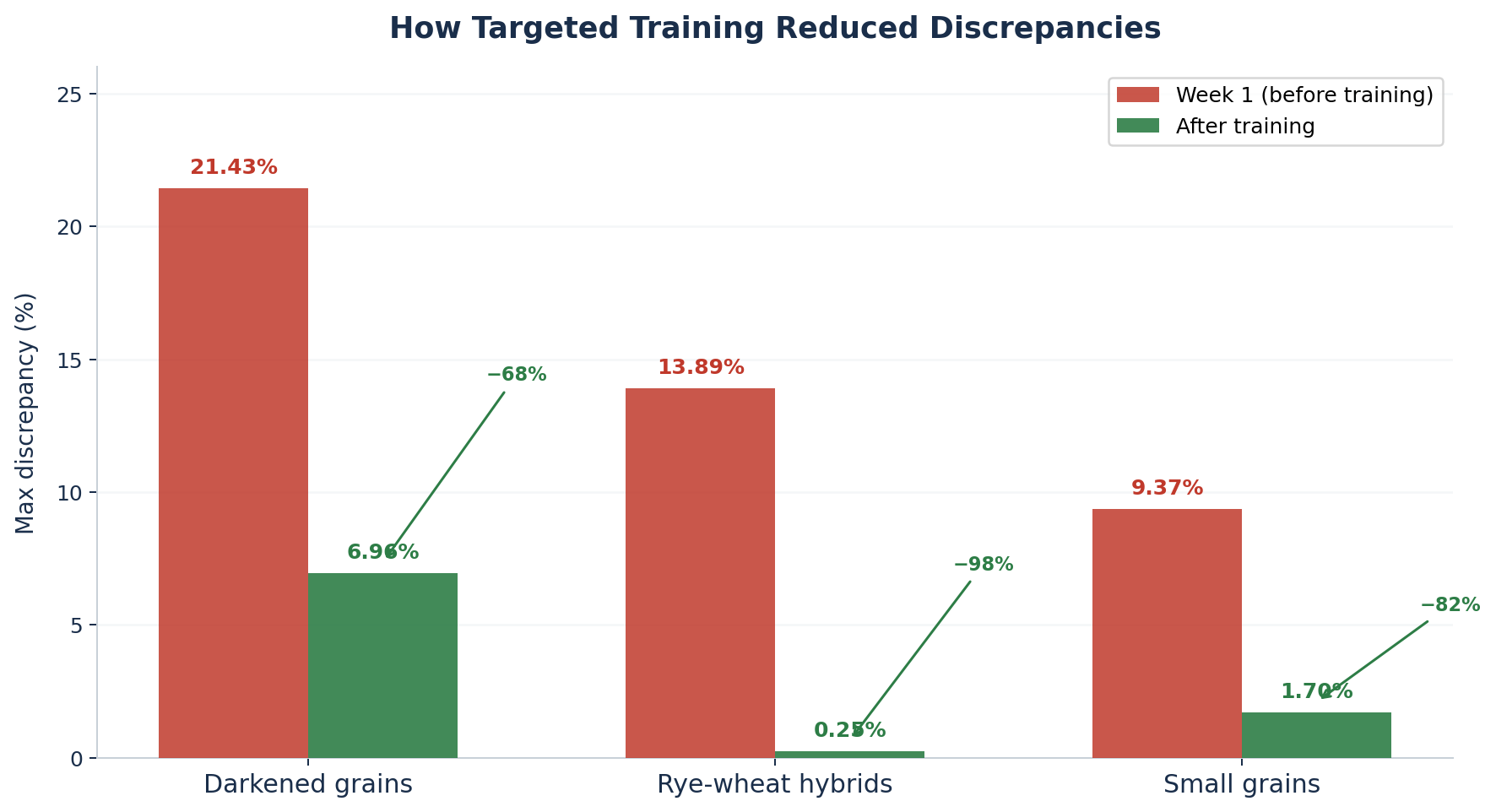
- Hybrides seigle-blé : de 13,89% de divergence maximale à 0,25%, soit une réduction de 98%
- Petits grains : de 9,37% à 1,70%, soit une réduction de 82%
- Grains foncés : de 21,43% à 6,96%, soit une réduction de 68%
Chaque amélioration provient du même mécanisme : des données plus ciblées, un meilleur étiquetage et une définition plus claire de la limite de classification. Le modèle n’est pas devenu plus intelligent au sens général du terme ; il est devenu plus performant sur des cas spécifiques et complexes, car il a été entraîné sur un plus grand nombre d’exemples pertinents.
Voilà à quoi ressemble le développement de l’IA en pratique.
Phase 2 : L’épreuve finale
Le 21 janvier 2026, après quatre mois de tests en parallèle, nous avons organisé la session de validation officielle.
Cinq techniciens de laboratoire spécialisés ont analysé indépendamment 16 échantillons de blé. GrainODM a analysé les mêmes échantillons. Les résultats de chacun sont restés confidentiels jusqu’à la fin. Chaque échantillon a été évalué selon 18 catégories d’impuretés, aboutissant à un classement qualitatif complet.
C’était le moment décisif. En cas de succès, le système passait en production. En cas d’échec, nous devions revoir notre copie.
Les résultats
| Indicateur | Résultat |
|---|---|
| IA en accord avec au moins 1 technicien | 96,2% |
| IA en accord avec 3 techniciens sur 5 | 95% |
| Taux de concordance moyen de l'IA avec les techniciens | 93,5% |
| IA en accord simultané avec les 5 techniciens | 85% |
Deux catégories d’impuretés ont atteint 100 % de concordance entre l’IA et tous les techniciens (balles et grains germés), tandis que d’autres – graines étrangères, grains endommagés – laissent encore une marge de progrès.
Ce que ces chiffres signifient vraiment
Voici le contexte qui rend ces résultats si parlants.
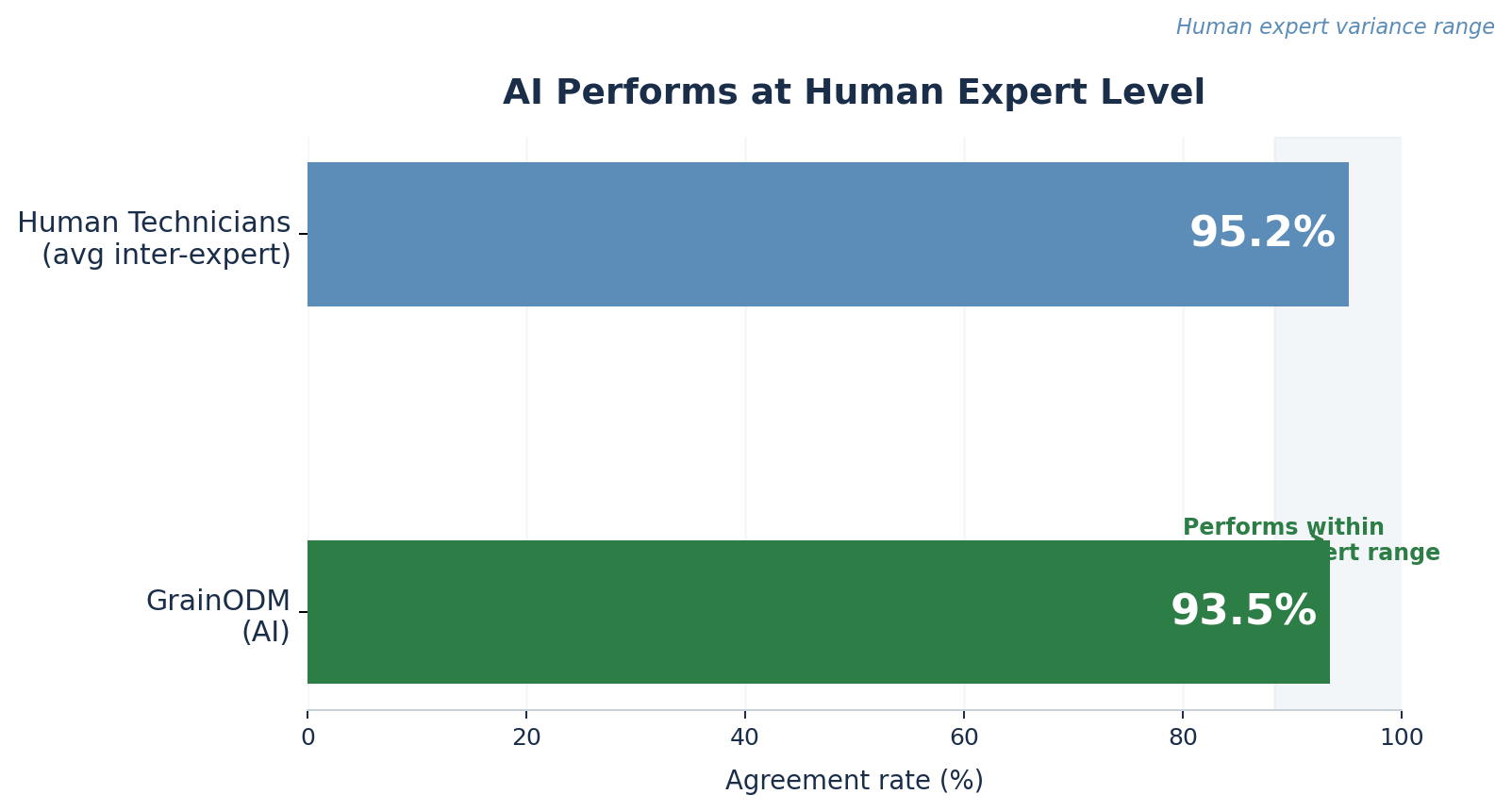
Lorsque les cinq techniciens ont évalué les mêmes échantillons indépendamment, leur taux de concordance moyen entre eux était de 95,2%. Ce sont des experts, mais ils restent humains : le jugement subjectif sur de subtiles distinctions visuelles explique pourquoi ils n’aboutissent pas toujours exactement au même résultat chiffré.
GrainODM a obtenu un taux de 93,5%.
Ce chiffre se situe au cœur de la marge de divergence naturelle entre experts. L’IA ne s’en approche pas, elle est dedans. Elle atteint le niveau de performance d’un technicien qualifié. D’un point de vue statistique, ajouter GrainODM à un processus d’évaluation équivaut à intégrer un sixième expert à l’équipe.
Pour préciser ce que cela signifie concrètement : lorsque les cinq techniciens ont noté les mêmes 16 échantillons dans des conditions identiques et en suivant le même règlement de classification, ils n’ont pas abouti à une décision unanime sur la classe de qualité finale pour 6 échantillons sur 16. Pour 2 de ces échantillons, il s’agissait d’un véritable partage 3 contre 2 — ce qui signifie qu’un même lot, évalué par un autre groupe de techniciens un autre jour, aurait pu se voir attribuer une classe différente.
La classification au niveau de la classe de qualité reste donc, par nature, un jugement d’expert – même lorsque tous s’appuient sur le même référentiel.
C’est précisément là que la notion de constance prend tout son sens. GrainODM applique la même logique à chaque échantillon, à chaque fois — sans variation entre équipes ou horaires, sans fatigue accumulée, sans dérive subjective au fil du temps. À données d’entrée identiques, le système produit des résultats identiques – ce qu’aucun évaluateur humain ne peut garantir à grande échelle.
La décision : passage en production
Le projet pilote a satisfait aux critères de validation. Les résultats ont montré que l’IA peut travailler au niveau expert dans les conditions réelles de réception.
Lots de céréales réels. Classifications à impact financier réel. Les résultats du système sont directement utilisés pour les décisions de classement de la qualité des céréales — de la Classe 1 à la Classe 4 — qui déterminent le prix, le stockage et les filières d’utilisation. Ce n’est pas une simulation. Les enjeux sont réels.
Ce que cela signifie pour le contrôle qualité des céréales
L’évaluation de la qualité des céréales a toujours requis des compétences humaines. Cela ne changera pas.
Ce qui change, c’est la répartition de la charge de travail. Un système qui atteint le niveau de performance d’un expert humain — constant sur des milliers d’échantillons, jamais fatigué, détectant à la limite de la perception humaine — modifie la nature des tâches sur lesquelles les experts concentrent leur temps. La classification de routine est automatisée. Les cas limites, les lots ambigus, l’analyse des tendances par fournisseur : ces tâches restent du ressort des experts formés pour cette réflexion stratégique.
La question n’a jamais été de savoir si l’IA pouvait remplacer les techniciens céréaliers. La question était : l’IA peut-elle atteindre un niveau de fiabilité suffisant pour travailler à leurs côtés ?
Après 4 mois, plus de 600 tests et une validation officielle face à cinq experts indépendants, la réponse est oui.
Questions Fréquemment Posées
Sur 16 échantillons de blé et 18 catégories d'impuretés, l'IA a affiché une concordance moyenne de 93,5 % avec cinq techniciens indépendants. La concordance entre techniciens humains était de 95,2 %, l'IA se situait donc dans la fourchette naturelle des jugements experts.
Tous les échantillons provenaient de chargements réels de blé dans une installation commerciale. L'IA et l'équipe du laboratoire ont évalué les mêmes lots en parallèle sur environ quatre mois, couvrant des centaines de tests de réception de routine, et non un jeu de tests sélectionné à la main.
Les catégories les plus difficiles étaient les grains foncés, les hybrides seigle-blé et les grains petits ou échaudés, plus la fusariose. Un réentraînement ciblé a nettement réduit les erreurs sur les trois premières ; l'amélioration de la classification de la fusariose dépend encore de l'acquisition de davantage de données étiquetées de qualité.
Les chiffres de cette étude de cas s'appliquent au blé et aux normes de classement de ce site. En revanche, le processus de validation – faire tourner l'IA en parallèle, la comparer à plusieurs experts et itérer sur les cas les plus difficiles – peut être reproduit pour d'autres cultures, sites et schémas qualité.
The New Standard in Grain Purity Analysis
Data, not guesswork. Learn how GrainODM sets a new benchmark for digital grain inspection.