


4 hónap és több mint 600 vizsgálat után már csak egyetlen kérdés maradt: mi történik, ha 5 hivatásos gabonalaboránst és az AI-t ugyanazokkal a búzamintákkal szembesítjük? Vajon azonos eredményre jutnak?
Ez volt az a validációs feltétel, amiben a kísérleti projekt (pilot) elején megállapodtunk. Nincsenek enyhébb feltételek. Nincs ideális körülmények között mért átlageredmény. Öt független szakértő, egy AI-rendszer, egyetlen tesztkör – és az eredmény dönti el, hogy a GrainODM éles üzembe állhat-e.
Ez az esettanulmány bemutatja, hogyan jutottunk el idáig.
Miért nehezebb a gabona minősítése, mint amilyennek látszik
A búza nem csupán búza. Amikor egy tétel beérkezik egy gabonafeldolgozó telephelyre, egy képzett laboráns több tucat minőségi paraméter alapján minősíti. Ebben a pilot projektben 18 különálló idegenanyag-kategóriát követtünk nyomon, többek között:
- fuzárium által károsított szemeket (gombás betegség)
- árpát, zabot, rozst és tritikálét (rozs–búza hibrid)
- töredék / tört szemeket és elszíneződött szemeket
- kártevők által rágott, léha / töppedt és csírázott szemeket
- egyéb idegen anyagokat, idegen magvakat, zsírtartalmat, pelyvát, valamint a gabona- és szemét jellegű idegen anyagok teljes mennyiségét
Bármely kategóriában bekövetkező legkisebb, akár tizedszázalékos eltérés is egy tételt az 1. osztályból a 4. osztályba sorolhat át, ami közvetlen pénzügyi következményekkel jár. Ha szeretné látni, hogyan kezelik a szabályozók ezeket a határértékeket tágabb értelemben, ezt a gabona szennyeződési szabványok útmutatóban foglaljuk össze. Az egyedi hibák (pl. csírázott szemek) hagyományos laborokban történő felismeréséről a búza csíraképződésének felismerése esettanulmányunkban olvashat.
A folyamat emellett eredendően szubjektív. Két tapasztalt laboráns, aki ugyanazt az elszíneződött szemeket tartalmazó tételt vizsgálja, nem mindig állapít meg azonos százalékos arányt. Ez nem a szakértelem hiánya, hanem a szemrevételezéses vizsgálat természetéből fakad, amely valós munkakörülmények között zajlik.
Pontosan ezért döntöttünk úgy, hogy a rendszert nem egyetlen laboránshoz mérjük. Öt független szakértő adta meg számunkra az emberi szakértői véleménykülönbség természetes tartományát – és egy reális viszonyítási alapot.
1. fázis: A pilot elindul – és felszínre kerülnek a nehéz esetek
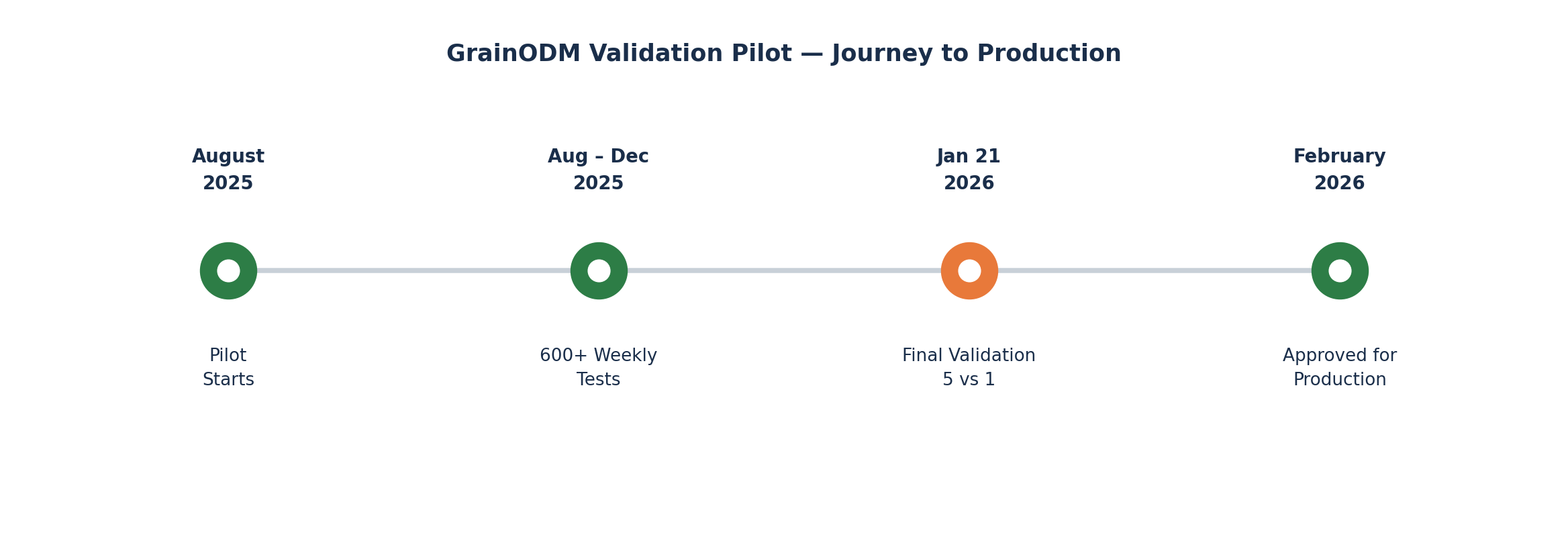
A pilot projekt 2025 augusztusában indult egy nagy mezőgazdasági holdinggal közösen. A GrainODM párhuzamosan futott az ügyfél meglévő laboratóriumi folyamataival: ugyanazokat a beérkező gabonatételeket elemeztük, egy időben. A csapat hetente közösen értékelte az eredményeket, és a tanulságokat visszatáplálta a modellbe.
A négy hónap alatt több mint 600 egyedi vizsgálatot végeztünk.
Az első hetek voltak a legtanulságosabbak. Három kategória bizonyult a legnehezebbnek:
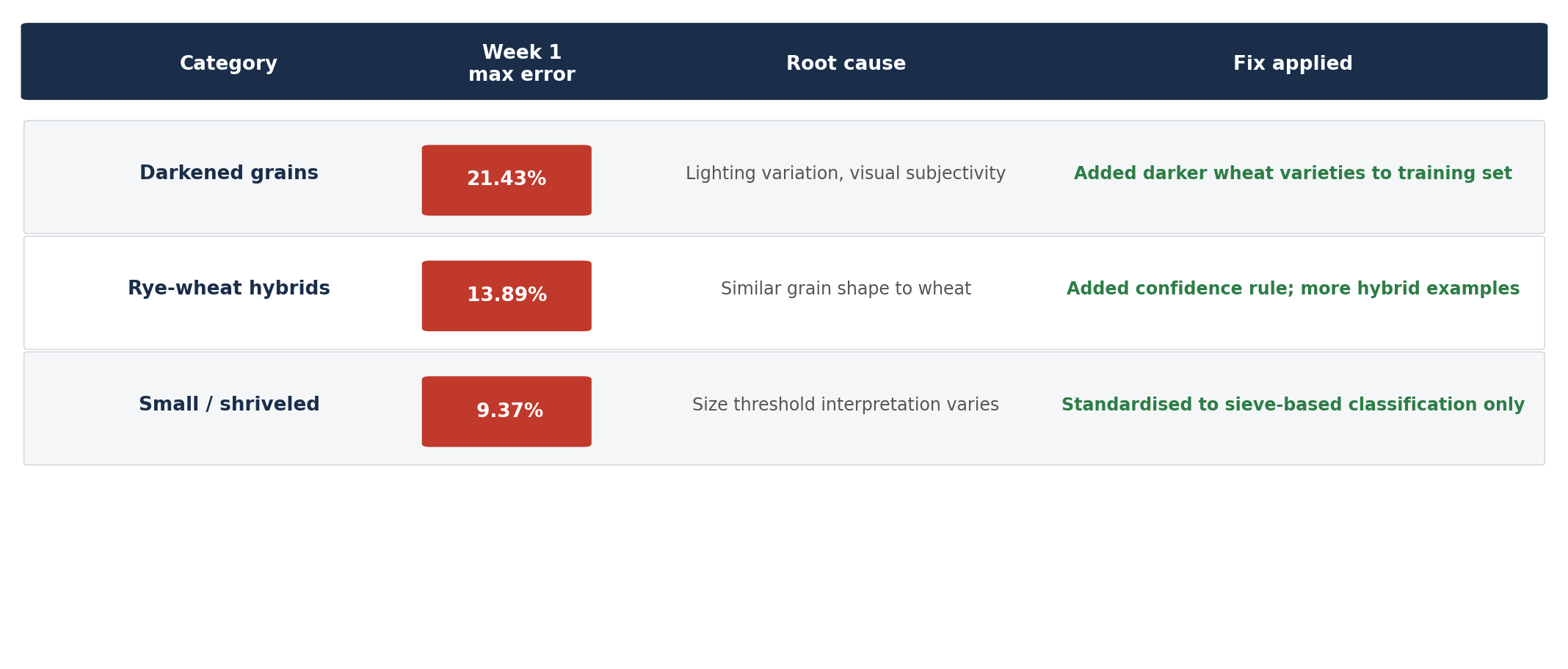
- Az elszíneződött szemek esetében a maximális eltérés az 1. héten 21,43% volt. A kiváltó ok: a megvilágítás ingadozása a képalkotás során, valamint a fogalom szubjektivitása – még a laboránsok is máshogy ítélték meg az “elszíneződött” szemek arányát az adott búzafajtától függően.

- A rozs-búza hibridek esetében a maximális eltérés 13,89% volt. A tritikálé – egy rozs-búza keresztezés – morfológiailag annyira hasonlít a búzához, hogy a modell elegendő tanítóminta hiányában nehezen tudta következetesen megkülönböztetni őket.

- A léha / töppedt szemek esetében az eltérés elérte a 9,37%-ot. A probléma az volt, hogy a modell vizuális alapon, míg a laboratórium szitaméret alapján határozta meg a “kis” méretű szemeket.
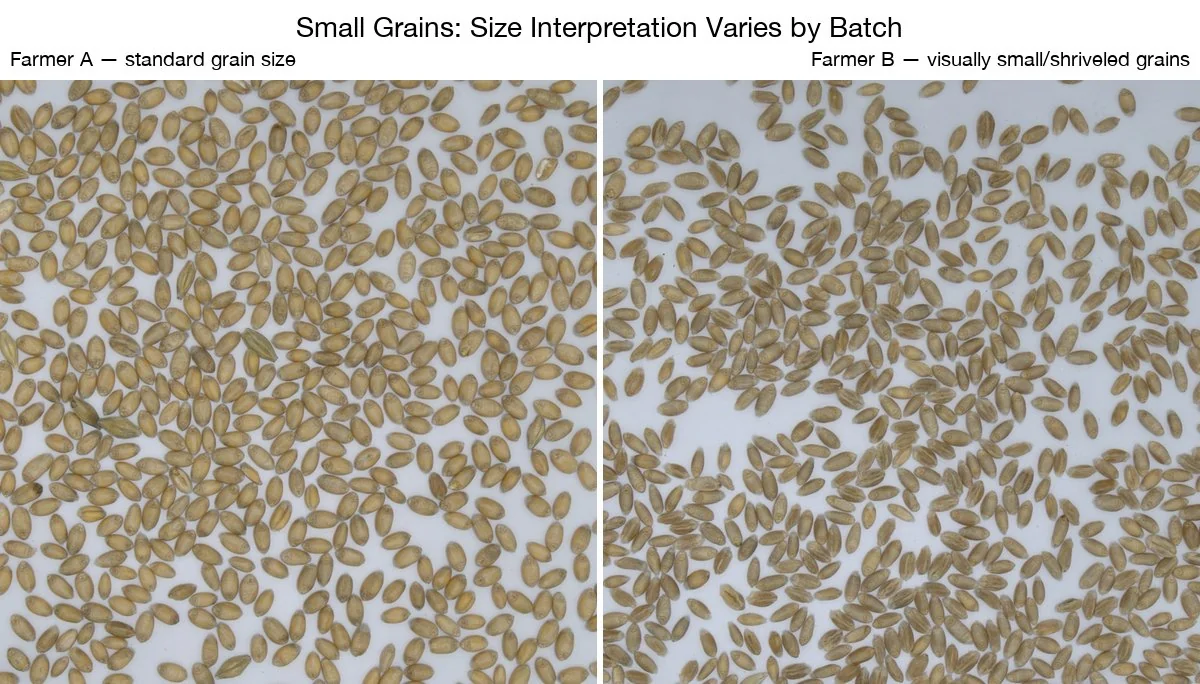
Ezek nem véletlenszerű hibák voltak. Mindegyiknek egyértelmű, diagnosztizálható oka volt – ami azt is jelentette, hogy mindegyikre létezett egyértelmű megoldás.
A visszacsatolási kör: adatoktól a fejlődésig
Ez az AI-fejlesztés azon része, amelyet könnyű alábecsülni. A modell nem egy fix rendszer volt, amit telepítettünk és magára hagytunk. Minden hét eredményeit kielemeztük, azonosítottuk a kiváltó okokat, és frissítettük a tanító adathalmazt. Több minta. Pontosabb címkézés. Célzott szabályok a szélsőséges esetekre.
A modellfrissítések mérföldkövei a pilot során:
| Mikor | Frissítés |
|---|---|
| Első hét | Enyhén elszíneződött szemek eltávolítása az adathalmazból; az egészséges búzafajtákra vonatkozó minták bővítése |
| Második hét | Konfidencia-küszöb bevezetése a rozsfelismerésnél – a bizonytalan besorolásokat a rendszer elutasítja, ahelyett, hogy megpróbálná megbecsülni őket |
| Ötödik hét | Új modell telepítése: a tritikálé és a világosabb szemek pontosabb felismerése |
| Hatodik hét | Fuzárium frissítés: rózsaszín és fehér fuzáriumos minták hozzáadása; a címkék pontosítása az egyértelmű tüneteket mutató esetekben |
| Hetedik hét | Léha szemek: a 2 mm-nél nagyobb szemek kizárása a töppedt kategóriából a laboratóriumi, szitaalapú szabványnak való megfelelés érdekében |
A módszer tudatos: azonosítjuk, hol tér el a modell a szakértői ítélettől, megértjük, miért, majd több, az adott esetet lefedő adattal bővítjük a rendszert, újratanítjuk, és újra mérünk. Így javul lépésről lépésre az AI teljesítménye.
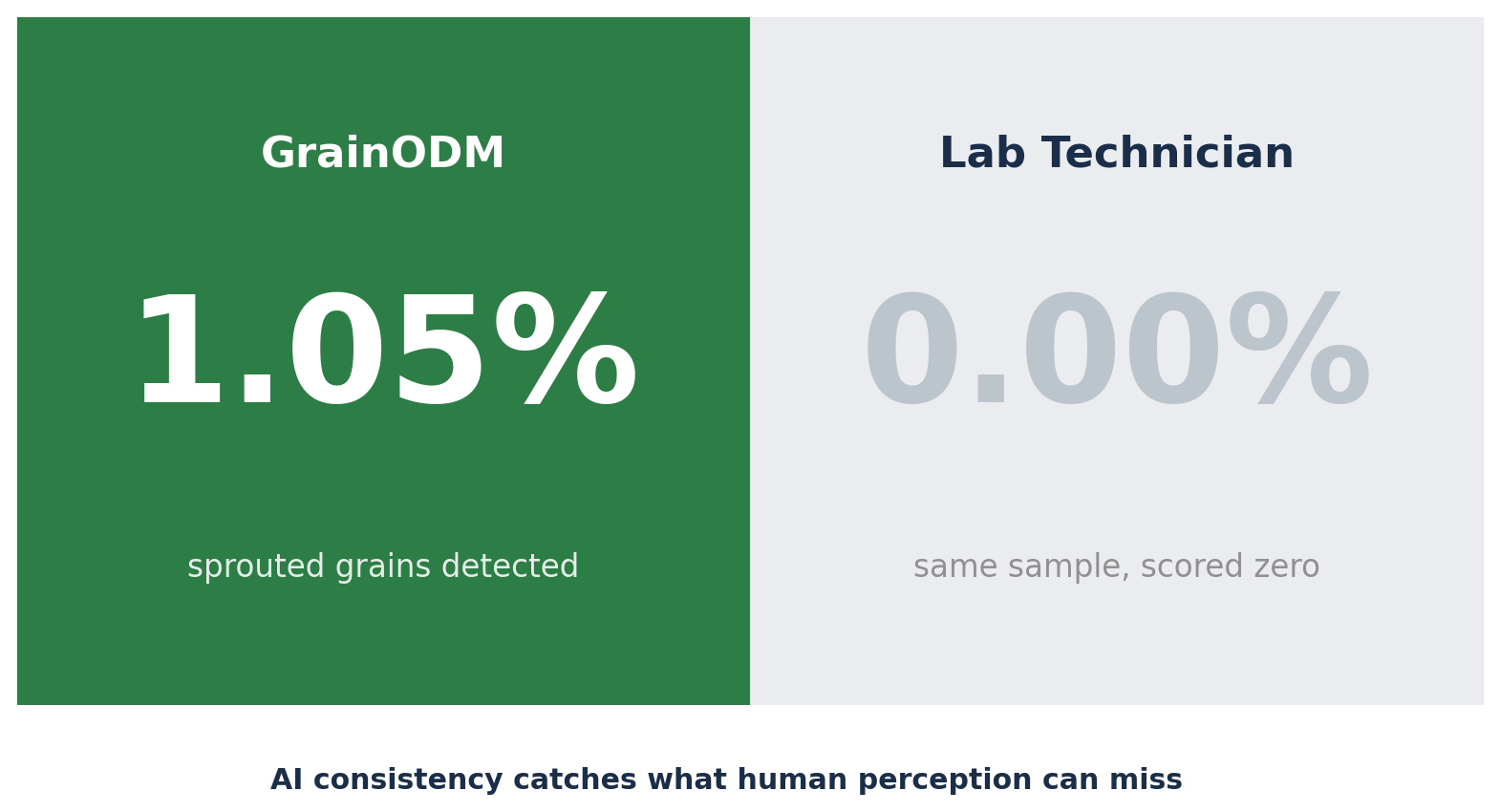
Ugyanebben az időszakban valami más is kiderült a heti kiértékelések során. Több minta esetében a GrainODM olyan szennyeződéseket jelzett, amelyeket a labor nullának, azaz nem létezőnek minősített:
| Szennyeződés típusa | GrainODM észlelés | Labor eredmény |
|---|---|---|
| Csírázott szemek | 1,05% | 0,00% |
| Csírázott szemek | 0,95% | 0,00% |
| Sérült szemek | 0,90% | 0,00% |
| Árpa | 0,08% | 0,00% |
Az AI nem tévedett. Az emberi észlelés határán talált rá azokra az egyedi szemekre, amelyek egy hosszú műszak során, egy egyébként tisztának tűnő tételben könnyen elkerülhetik a figyelmet. Minden egyes szem következetes vizsgálata minden mintában olyasmi, amiben a gépek hosszú távon egyszerűen jobbak az embernél.
A visszacsatolási kör eredményei
A szeptember 29. – október 3. közötti teszthétre a fejlődés már számszerűsíthető volt:
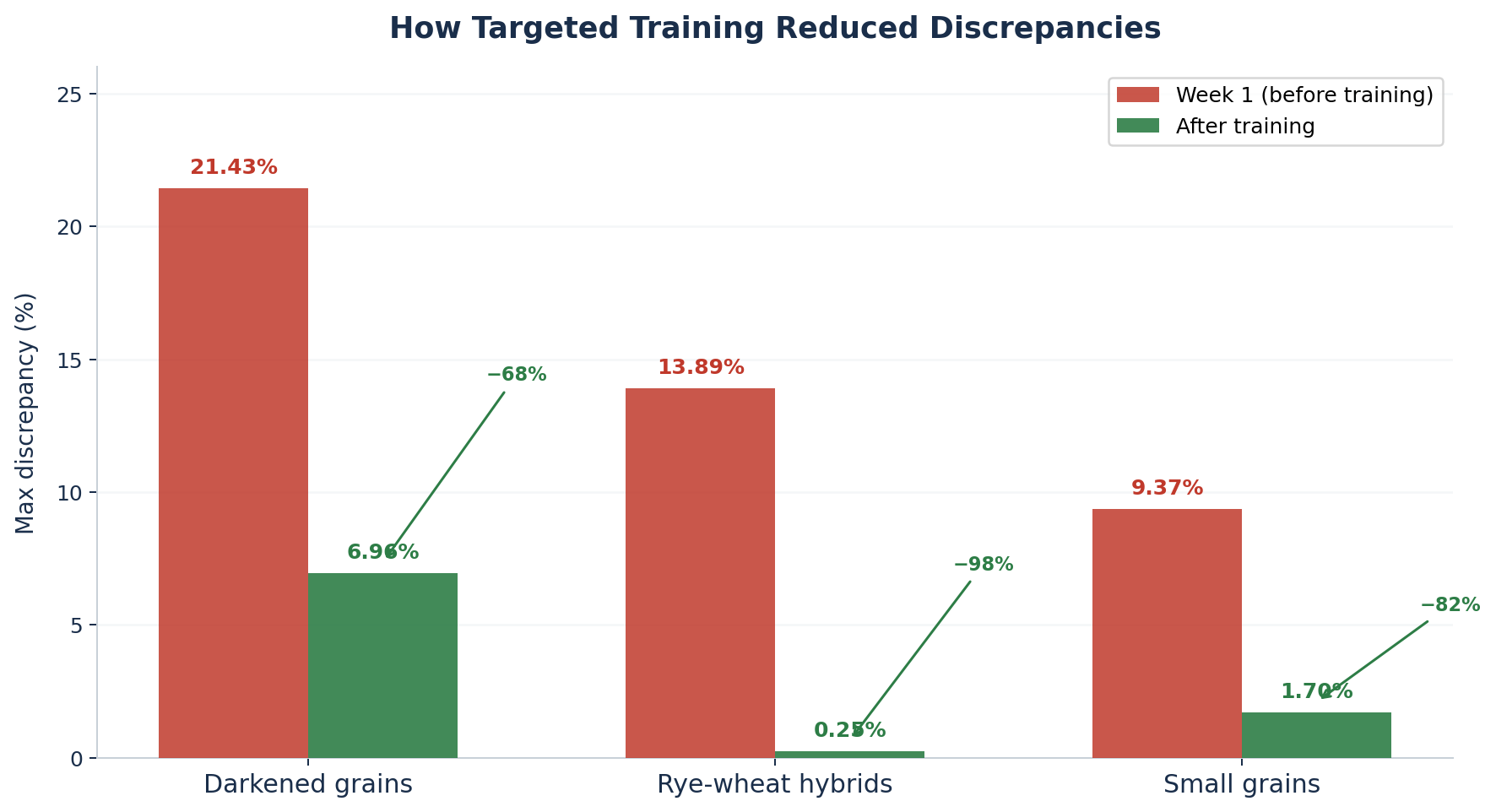
- Rozs-búza hibridek: a 13,89%-os maximális eltérés 0,25%-ra csökkent – ez 98%-os javulás
- Léha szemek: a 9,37%-os eltérés 1,70%-ra csökkent – ez 82%-os javulás
- Elszíneződött szemek: a 21,43%-os eltérés 6,96%-ra csökkent – ez 68%-os javulás
Minden javulás ugyanannak a folyamatnak volt köszönhető: célzottabb adatok, pontosabb címkézés és a besorolási határok egyértelműbb meghatározása. A modell nem általánosságban lett okosabb, hanem a konkrét, nehéz esetek felismerésében vált sokkal jobbá, mert ezekből több példát kapott.
Így néz ki az AI-fejlesztés a gyakorlatban.
2. fázis: A végső teszt
2026. január 21-én, négy hónapnyi párhuzamos tesztelés után, megtartottuk a hivatalos validációs tesztet.
Öt hivatásos gabonalaboráns egymástól függetlenül elemzett 16 búzamintát. A GrainODM ugyanazokat a mintákat vizsgálta. Senki sem látta a többiek eredményeit, amíg a teszt le nem zárult. Minden mintát 18 idegenanyag-kategória szerint minősítettünk, teljes körű minőségi besorolással.
Ez volt a döntő pillanat. Ha a rendszer átmegy a validáción, éles üzembe áll. Ha nem felel meg, visszatérünk a tervezőasztalhoz.
Az eredmények
| Mutató | Eredmény |
|---|---|
| Az AI eredménye legalább 1 laboránséval egyezett | 96,2% |
| Az AI eredménye az 5-ből 3 laboránséval egyezett | 95% |
| Az AI átlagos egyezése az összes laboránssal | 93,5% |
| Az AI eredménye mind az 5 laboránséval egyezett | 85% |
Két idegenanyag-kategória ért el 100% egyezést az AI és az összes laboráns között (pelyva és csírázott szemek); másoknál – pl. idegen magvak, sérült szemek – továbbra is van hová fejlődni.
Mit jelentenek valójában a számok
Íme a kontextus, amely ezeket az eredményeket igazán jelentőssé teszi.
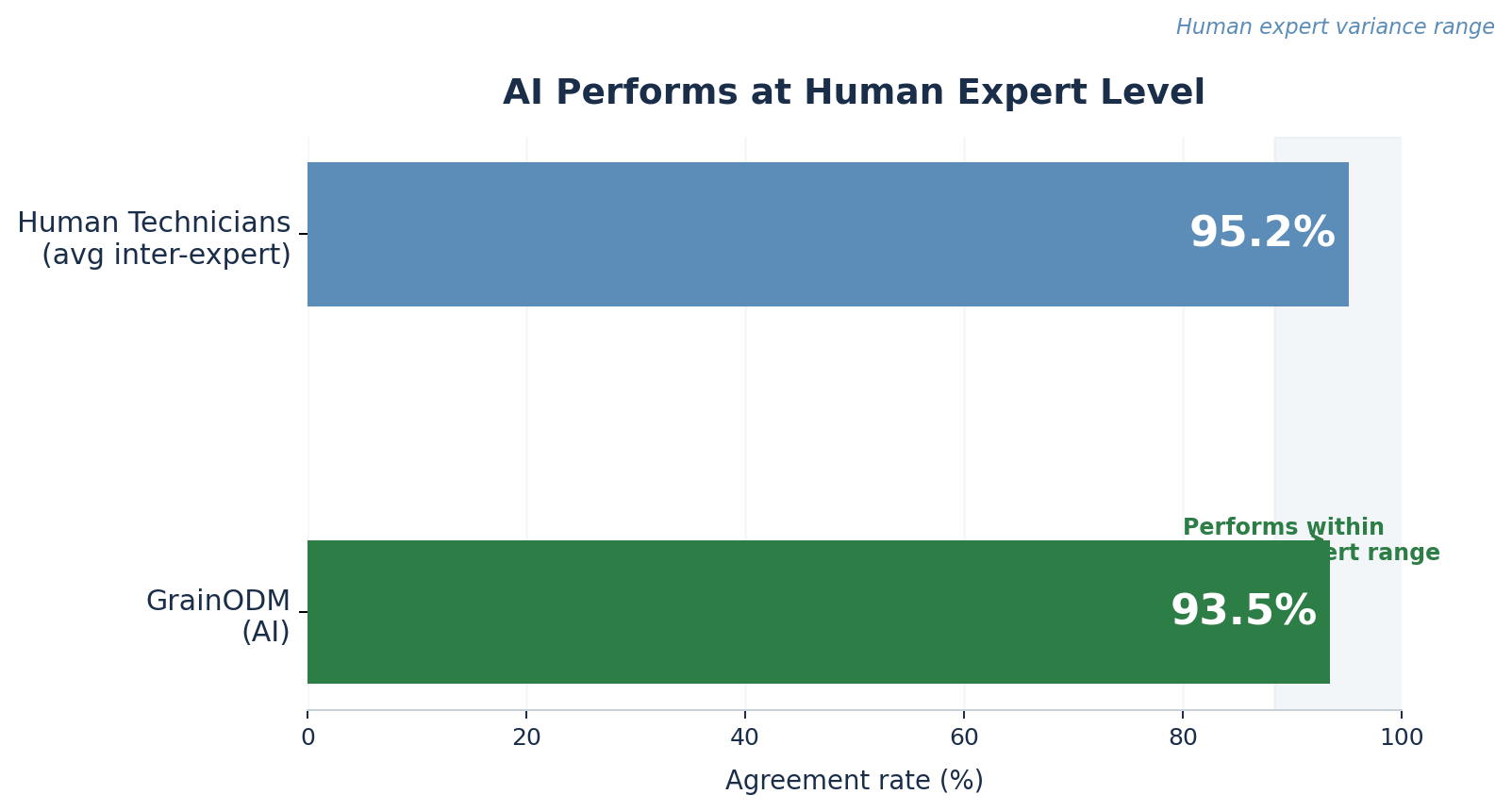
Amikor az öt laboráns egymástól függetlenül minősítette ugyanazokat a mintákat, az egymás közötti átlagos egyezésük 95,2% volt. Bár szakértők, de ők is emberek: a finom vizuális különbségeken alapuló szubjektív ítélet azt jelenti, hogy nem mindig jutnak pontosan ugyanarra az eredményre.
A GrainODM 93,5%-os eredményt ért el.
Ez az érték az emberi szakértői véleménykülönbség természetes szórásán belül helyezkedik el. Nem alulról közelíti azt, hanem benne van. Az AI egy képzett laboráns szintjén teljesít. A GrainODM bevonása egy minősítési folyamatba statisztikailag egyenértékű azzal, mintha egy hatodik szakértővel bővítenénk a csapatot.
Ha ezt kontextusba helyezzük: amikor az öt laboráns ugyanazt a 16 mintát azonos körülmények között, ugyanannak a minősítési szabálykönyvnek megfelelően értékelte, 16-ból 6 minta esetében nem jutottak egyhangú végső osztályba sorolásra. Két esetben a vélemények ténylegesen 3–2 arányban oszlottak meg – ami azt jelenti, hogy ugyanaz a tétel egy másik laboránscsoporttal, egy másik napon akár másik minőségi osztályt is kaphatott volna.
A minősítés osztályszinten tehát lényegében szakmai mérlegelés kérdése – még akkor is, ha mindenki ugyanabból a szabálykönyvből dolgozik.
Itt válik igazán fontossá a következetesség. A GrainODM minden egyes mintára, minden alkalommal ugyanazt a logikát alkalmazza – nincs műszakok közötti szórás, nincs felgyülemlő fáradtság, nincs lassú, szubjektív „elpártolás” az évek során. Az azonos bemenet azonos kimenetet eredményez – ezt pedig egyetlen emberi értékelő sem tudja nagy volumenben garantálni.
A döntés: engedélyezés éles üzemre
A pilot sikeresen vette a validációs akadályt. Az eredmények igazolták, hogy az AI szakértői szinten tud dolgozni valós átvételi feltételek mellett.
Valódi gabonatételek. Valódi pénzügyi következményekkel járó besorolások. A rendszer kimenetei közvetlenül befolyásolják a gabona minőségi osztályozását – 1-től 4-ig –, amely meghatározza az árazást, a tárolást és a további felhasználást. Ez nem egy tesztkörnyezet. Itt valódi a tét.
Mit jelent ez a gabona minőség-ellenőrzése számára
A gabona minőségének értékelése mindig is szakképzett embereket igényelt. Ez a jövőben sem változik.
Ami változik, az a munkaterhelés eloszlása. Egy rendszer, amely emberi szakértői szinten teljesít – több ezer mintán át is következetesen, fáradhatatlanul, az emberi érzékelés határán is észlelve – megváltoztatja, hogy a szakértők mire fordítják az idejüket. A rutin besorolás automatizálható. A szélsőséges esetek, a problémás tételek, a beszállítók közötti trendek elemzése – ezek továbbra is a szakemberek feladatai maradnak.
A kérdés soha nem az volt, hogy az AI képes-e helyettesíteni a gabonalaboránsokat. A kérdés ez volt: képes-e az AI elég megbízhatóan teljesíteni ahhoz, hogy mellettük dolgozzon?
4 hónap, több mint 600 vizsgálat és egy öt független szakértővel elvégzett hivatalos validáció után a válasz: igen.
Gyakran Ismételt Kérdések
16 búzaminta és 18 szennyeződési kategória esetén az AI átlagosan 93,5%-os egyezést ért el öt független laboránssal. Az emberi laboránsok egymás közötti egyezése 95,2% volt, az AI tehát a szakértői vélemények természetes szóródásán belül maradt.
Minden minta valódi, kereskedelmi létesítménybe érkező búzaszállítmányokból származott. Az AI és a laboratóriumi csapat körülbelül négy hónapon át párhuzamosan értékelte ugyanazokat a tételeket, százabb rutin átvételezési tesztet lefedve, nem kézzel válogatott tesztkészletet.
A legnehezebb kategóriák a besötétedett szemek, a tritikale és a kis vagy ráncos szemek voltak, plusz a fusarium. A célzott újraképzés jelentősen csökkentette a hibákat az első három kategóriában; a fusarium osztályozás javítása továbbra is több, jó minőségű címkézett adat gyűjtésétől függ.
Az eredmények ebben az esettanulmányban a búzára és ennek a létesítménynek a minősítési szabványaira vonatkoznak. A validációs folyamat – AI párhuzamos futtatása, összehasonlítás több szakértővel, a legnehezebb esetek iteratív finomítása – azonban megismételhető más növények, létesítmények és minőségi sémák esetében.
The New Standard in Grain Purity Analysis
Data, not guesswork. Learn how GrainODM sets a new benchmark for digital grain inspection.